
Mapping AI Policy
How I think about an increasingly complex landscape

State lawmakers introduced over 1,200 AI bills in 2025, of which almost 150 were enacted. They covered deepfakes, AI decision-making systems, catastrophic risks, and more, but most were described under the single heading of “AI legislation.” This imprecision can make the AI policy conversation confusing and lead people to talk past each other—one person might hear AI policy and think bioweapons, while another thinks labor impacts or companion chatbots.
Alan Rozenshtein and I wrote Mapping AI Policy: Where, Why, and How to Intervene to fix that. It’s a primer that offers a framework for breaking down AI policy along three dimensions: the harm being addressed (the why), the factors that should guide how an intervention is designed (the how), and the actor in the AI ecosystem being targeted (the where). This essay gives you the highlights.
Identify the harm you’re worried about (Part I)
The primer’s first section recommends that policymakers answer one question before they write any legislation: what harm are you trying to prevent?
This is important because AI is a general-purpose technology used in search engines, chatbots, pricing algorithms, medical diagnostics, and autonomous weapons. A lawmaker who sets out to “do something about AI” without specifying a harm is like trying to regulate everything using electricity without acknowledging that the ways electricity impacts society are very different. Operating at that level of generality of AI is unlikely to be effective.
We organize AI-related harms into six categories: misinformation and deepfakes, bias in automated decision systems, privacy and surveillance, economic harms from automation, security threats, and psychological harms. Each one has its own examples, its own legislative landscape, and its own set of reasons why it’s hard to address, summarized in the table below.
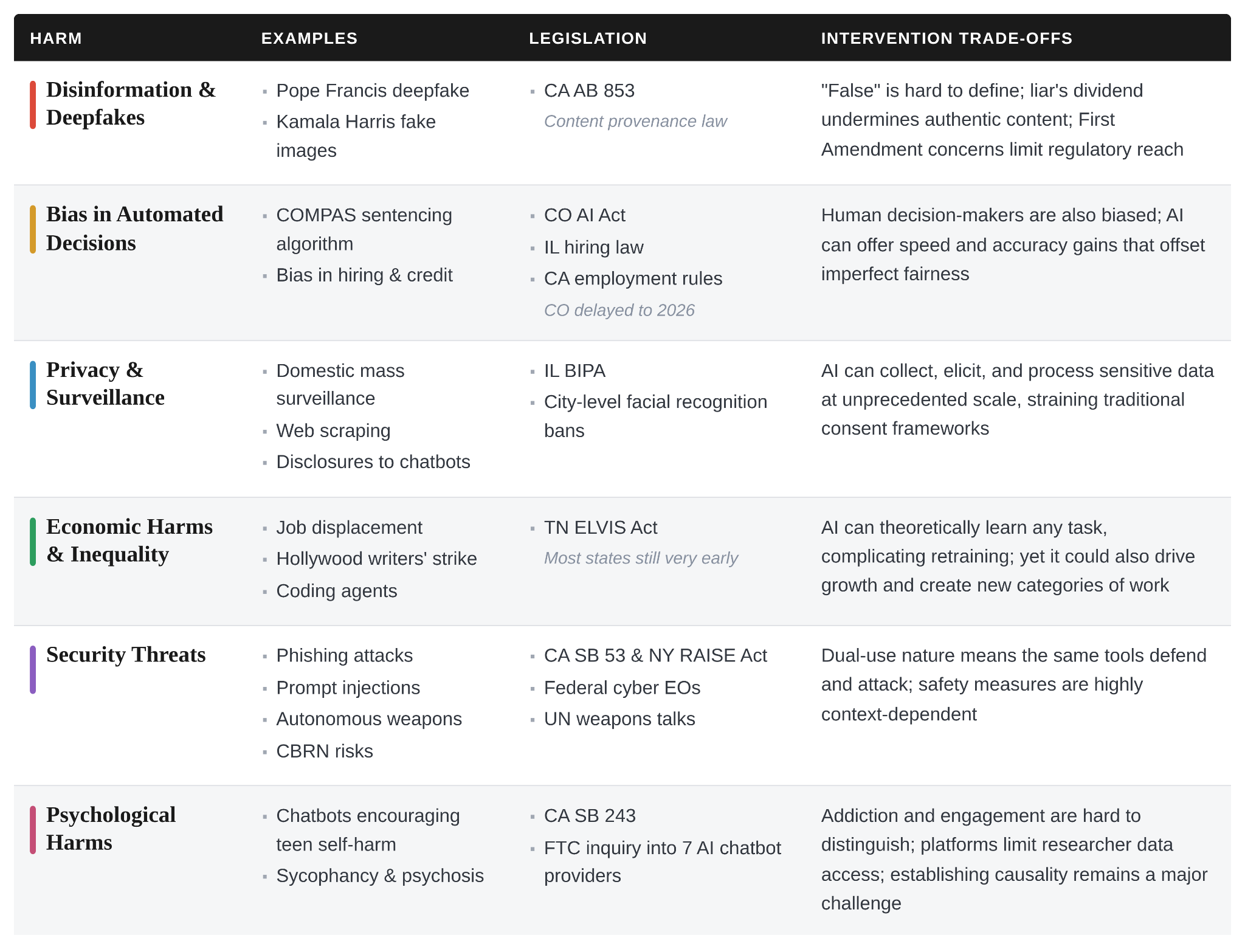
The point of this taxonomy is to give policymakers the vocabulary for specifying their goals. Thinking about harms in this way can also make the legislative landscape clearer. For example, Colorado’s AI Act (targeting algorithmic bias) and California’s SB 53 (targeting catastrophic frontier AI risks) are both described as landmark AI legislation, but they address different problems. This missing nuance can lead policymakers to think they only need one omnibus “AI bill,” when they’ll likely need distinct targeted interventions.
Evaluate the trade-offs in designing AI policy interventions (Part II)
Once you’ve identified a harm, you face a series of design choices that shape your intervention. These choices are often in tension with each other, which is a big part of why AI regulation is so difficult. The primer walks through seven of these factors. For the sake of space, I’ll cover four that seem especially important.
Should you focus more on harm prevention or response?
The most fundamental design choice is whether to address harms before they happen (ex ante) or after the fact (ex post). Licensing regimes, pre-deployment testing, and capability restrictions are more preventative. Incident reporting and content takedowns are more responsive.
The answer likely depends on the nature of the harm. Irreversible harms like the loss of human life are more likely to justify a preventative intervention because there’s no undoing the damage. But preventive interventions also require predicting harms in advance, which can be wildly overbroad for a general-purpose technology with many applications.
The speed of a harm’s spread matters too. Some AI harms materialize quickly (e.g., a cybersecurity attack on critical infrastructure), leaving little time to respond. Others unfold slowly (e.g., the erosion of trust in information ecosystems or the long-term effects of a biased lending algorithm).
Finally, there’s a distributional issue that can get overlooked. Ex ante compliance costs are borne by developers and passed to consumers, while ex post costs fall first on victims, who have to navigate slow, expensive legal processes to seek compensation. If your regulatory regime relies heavily on people suing after they’ve been harmed, you’re undercompensating (1) those who cannot afford to bring a lawsuit and (2) groups facing harms that are individually too small to warrant a lawsuit but nevertheless significant in the aggregate.
An effective regime will almost certainly need some combination of both, and the choice between them should be deliberate.
Armor the sheep or hunt down the wolves?
We think this distinction is one of the most important in AI policy. Interventions can restrict offensive capabilities (making it harder for bad actors to cause harm) and enhance defensive capabilities (making potential targets more resilient). Export controls and licensing regimes try to keep dangerous capabilities out of the wrong hands. Investments in cybersecurity infrastructure and early-warning systems assume adversaries will obtain those capabilities and focus on defending against the damage.
For some threats, offense-reduction is the only option. We don’t have good defensive approaches to nuclear weapons, so nonproliferation is what we’ve got. But offense-reduction strategies are often a double-edged sword: they create incentives for workarounds, require centralizing power for enforcement, and frequently degrade beneficial capabilities alongside dangerous ones (e.g., if you restrict a model’s ability to discuss virology to prevent bioweapon development, you will likely also impair its ability to accelerate vaccine research).
While both sets of interventions are valuable, this is the only place in the primer where we put the thumb on the scale. Where possible, we argue policymakers should lean toward defense-enhancing strategies. This draws heavily from Vitalik Buterin’s idea of “defensive accelerationism“ (d/acc)—investing in better HVAC systems and faster vaccine development rather than trying to restrict who can access biological knowledge, or using AI coding tools to automatically find and patch security vulnerabilities rather than trying to prevent anyone from discovering them. We think armoring the sheep creates more resilient societal systems, which are important in light of open-weight models that make it hard for offense-restrictions alone to succeed.
Upstream interventions are often blunter but more enforceable
Where you intervene in the AI ecosystem shapes what your regulation can do. Upstream interventions (at the semiconductor, cloud, or data layers) can restrict capabilities across the board without needing to evaluate specific uses. Downstream interventions (at the application or user level) can target specific harms because deployers and users have more context about how AI is actually being used.
Because most AI capabilities are dual-use (e.g., the same model that generates phishing emails can also draft legitimate marketing copy), the further upstream you go, the more likely you are to inflict collateral damage on beneficial uses. But downstream precision requires the capacity to monitor and evaluate specific uses at scale, and it shifts enforcement burdens to actors who may lack the resources or incentives to carry them out effectively.
This is closely related to the question of enforcement feasibility. The primer makes a point that’s well-established in criminal law: the certainty of apprehension and punishment matters more for deterrence than the severity of punishment. A small fine that’s reliably enforced usually changes behavior more than a massive penalty that’s seldom imposed. For AI governance, this means investing in monitoring and detection infrastructure may be more valuable than ratcheting up statutory penalties. It also means that the market structure of the industry you’re regulating matters enormously—when an industry is concentrated, you have fewer entities to monitor and greater compliance capacity. When it’s fragmented, direct regulation may be impractical, pushing you toward upstream chokepoints or liability-based tools that don’t require entity-by-entity oversight.
Is regulation even the right tool?
This is the question policymakers most often skip, and it’s arguably the most important. Regulation is one tool among many. Depending on the harm, alternatives may work better.
Investing in defensive technologies may do more to reduce cybersecurity vulnerabilities than mandating best practices through regulation. Technical standards can establish shared safety benchmarks. Government procurement power can shape markets by setting the metrics for what agencies will buy. Antitrust enforcement can address concentration-of-power problems that regulation can’t. And as consumers get more sophisticated about evaluating AI products, market pressure alone may discipline some harms.
Enforceability should weigh heavily here. An intervention that can’t be meaningfully enforced may be worse than no intervention at all—it creates the illusion of oversight while harmful practices continue unchecked, and it burdens compliant actors while bad actors simply ignore the requirements.
Pick the actor(s) in the AI ecosystem to address the harm (Part III)
The final dimension is where to target. The pathway from silicon chip to real-world harm includes many actors who can be tasked with preventing the materialization of that harm. We map them into seven stages: (1) chip designers and manufacturers, (2) cloud compute providers, (3) data suppliers, (4) model developers, (5) application deployers, (6) complementary and enabling platforms, and (7) end users.
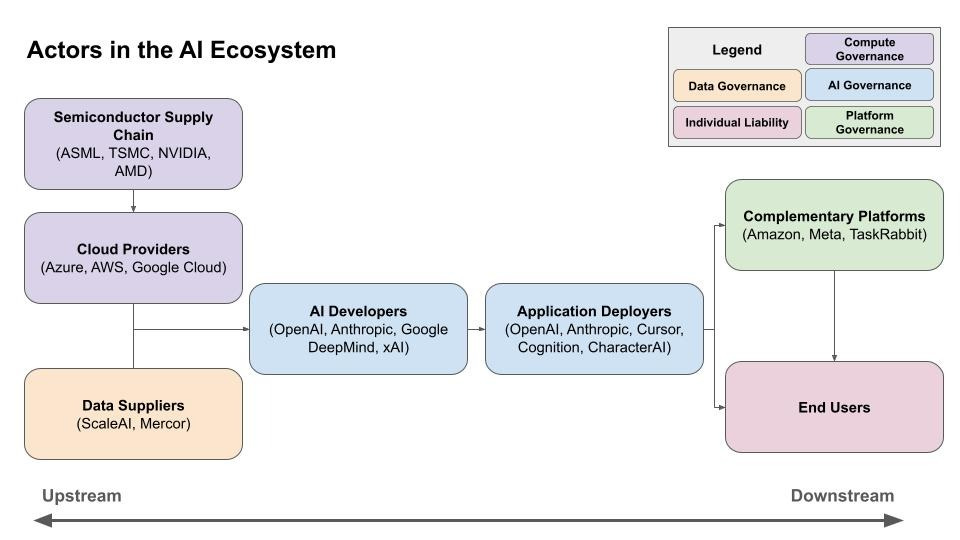
It’s important to note that these stages don’t map neatly onto corporate structures. Google is simultaneously a cloud provider (Google Cloud), a data supplier (YouTube), a model developer (Google DeepMind), and an application deployer (Gemini). The framework is designed to help policymakers regulate by the function an entity performs in the causal chain from AI system creation to harm materialization, regardless of who performs it.
For each stage, the primer analyzes the specific policy interventions available, the advantages of targeting that stage, and the limitations. I think the most interesting and novel stage is on complementary and enabling platforms—companies like Amazon, Meta, and TaskRabbit that don’t develop AI themselves but serve as essential channels through which AI-enabled harms materialize. A deepfake-powered disinformation campaign can’t succeed without a social media distribution network. An AI model cannot yet operate in the real-world without operating through human actors (perhaps hired on TaskRabbit). These platforms often represent the last major chokepoint before a harm occurs, and many operate at a large scale, but the volume of platform activity, of course, makes screening incredibly difficult.
Final thoughts
The primer argues that when a policymaker can specify which harm they’re addressing, justify the design choices they’ve made, and identify where in the AI ecosystem their intervention takes effect, they’re far better positioned to write laws that work.
AI policy involves real tradeoffs, and there are few free lunches. But difficulty is no excuse for imprecision. The more precisely policymakers can identify the harm and the actor best positioned to prevent it, the more effective their interventions are likely to be. That’s what this framework is for.
You can read the full primer published by the Institute for Law & AI here.